


I. Les pratiques agiles▲
I-A. Au plus profond de la culture agile▲
Des principes favorisant l'identification des actions d'amélioration sont intégrés au plus profond de la culture agile.
Par exemple :
Le développement itératif : répéter les mêmes activités permet d'améliorer sa pratique ;
La livraison fréquente : en s'assurant que les fonctionnalités développées sont remises rapidement entre les mains du client, l'agilité crée les conditions pour qu'une conversation ait lieu avec lui. S'il n'est pas satisfait, l'équipe cherche un moyen d'améliorer la situation ;
Les temps rétrospectifs : en réservant du temps pour réfléchir, l'équipe crée l'espace nécessaire pour le choix d'actions d'améliorations.
I-B. Les domaines privilégiés d'amélioration▲
Au fil des années, la communauté agile s'est constitué un riche catalogue de pratiques favorisant l'amélioration.
Le mouvement agile a été initié par des développeurs qui voulaient rompre avec des méthodes de projet contraignantes, des environnements de collaboration peu propices à l'épanouissement, et des pratiques d'ingénierie inefficaces. C'est la raison pour laquelle on peut trouver des pratiques agiles dans ces différents domaines. En voici quelques exemples significatifs.
I-B-1. L'organisation du travail▲
Comme le mécanicien qui sait repérer les anomalies dans le bruit répétitif du moteur, l'équipe identifie les effets des changements introduits par leurs décisions d'une itération à l'autre. Elle sait reconnaître des motifs récurrents, sait réagir et gérer le stress par le rythme du travail. Cette idée est reproduite de manière fractale jusqu'aux gestes du développement : la construction d'un programme est aussi une résolution successive de microproblèmes.
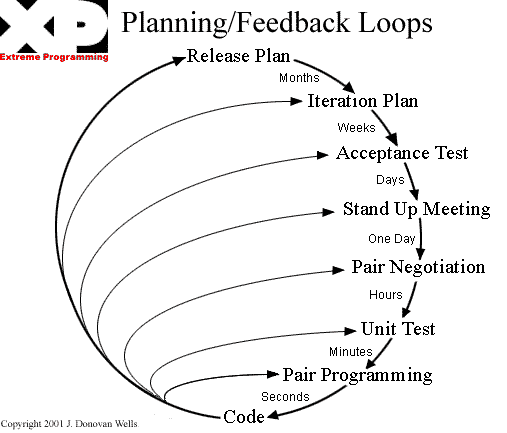
I-B-2. Les trucs de geeks▲
Le refactoring, les tests automatiques sont des leviers techniques d'amélioration du produit logiciel. Le développement piloté par les tests est un bon moyen de construire un design émergent, garant de l'évolutivité du code. Cela a pour effet de créer des degrés de liberté (fonctionnels, techniques) et assure la faculté de l'équipe de délivrer des évolutions à un rythme constant. Le refactoring est aussi une manière pour l'équipe de polir son code, de se l'approprier, le rendre plus habitable (cf Software Craftmanship).
Le binômage constitue également un levier d'amélioration. Par exemple, en associant un développeur d'une grande expérience métier avec un développeur nouveau dans l'équipe : le développeur nouveau avec son œil neuf peut apporter de la hauteur dans les solutions conçues, ainsi que son expertise technique. L'expert métier peut apporter au novice ses explications des concepts et techniques du projet.
I-B-3. La communication interpersonnelle▲
La qualité de la communication représente un axe majeur d'amélioration. Pour exploiter les bénéfices de la communication orale, il est conseillé de regrouper les postes de développement dans le même bureau. Quand la situation l'exige, l'équipe peut également augmenter la bande passante auprès de son client, par exemple en l'invitant plus fréquemment à des réunions de travail.
La construction d'équipe apparaît également comme un domaine d'action privilégié. Les coaches agiles puisent dans plusieurs domaines des sciences humaines et du coaching d'équipe (Virginia Satir, Ecole de Palo Alto, Core protocols, psychologie sociale) afin de guider les équipes dans l'amélioration de leur efficacité.
I-C. Trouver des leviers sur mesure▲
Le travail en équipe autoorganisée constitue un des principes fondamentaux de la culture agile (« The best architectures, requirements, and designs emerge from self-organizing teams »). Aussi, la source privilégiée de leviers d'amélioration réside dans l'équipe même.
La rétrospective, qu'elle ait pour objet une itération ou un projet entier, est le moment privilégié pour analyser la situation et choisir un levier d'amélioration. Chaque levier consiste à introduire ou ajuster une pratique issue du catalogue cité précédemment, ou une action concoctée sur mesure.
La diversité des points de vue de chaque individu est le gage du potentiel d'amélioration de l'équipe. Celle-ci doit s'efforcer d'exploiter au mieux cette richesse en partageant les informations pertinentes dont chacun peut disposer individuellement. Une fois ces informations partagées, nombre de techniques facilitent l'identification des problèmes à résoudre et la mise au point d'actions de résolution, mais toujours en s'appuyant sur le collectif.
Quelle qu'en soit la source d'inspiration et la méthode d'accouchement, une bonne action d'amélioration réunit les caractéristiques suivantes :
- elle est prometteuse : le bénéfice attendu est important. Ce bénéfice est évalué selon les critères propres aux participants ;
- à la portée des participants : ceux-ci sont en mesure de la mettre en œuvre avec les moyens à leur disposition ; ceci exclut les actions trop coûteuses ou en dehors du champ d'action ;
- elle remporte l'adhésion : c'est l'action qui fait consensus parmi les participants qui est choisie.
Les sections suivantes illustrent les retours d'expérience de praticiens agiles qui ont essayé des pratiques lean sur leurs projets pour aller plus loin dans l'amélioration.
II. Scène de crime : la mise en production qui ne devait pas échouer▲
II-A. L'odeur du napalm au petit matin▲
Un opérateur majeur propose un service grand public de télévision et vidéo à la demande. Il sert 40 millions d'accès par mois grâce à 250 000 lignes de code Java, une plateforme Linux/Apache/Tomcat/Mysql et un bus de données erlang RabbitMQ. Ce service est développé par mon équipe de huit développeurs et exploité par trois ingénieurs système. Cette équipe de développement pratique scrum et XP depuis quatre ans.
Un matin, je retrouve l'équipe système avec des cernes, en intervention depuis 5 h du matin. Le service web grand public est techniquement opérationnel, mais inaccessible. Malgré un rollback effectué sans problème, le monitoring du bus de données et des consommateurs des messages de statistiques est toujours rouge, signalant un incident. C'est pourquoi l'équipe système n'ose pas rouvrir le service au public.

Je vais voir l'ingénieur système pour l'aider à rétablir le service au plus tôt.
Nous essayons de relancer les consommateurs, sans succès. Je tente de lancer un consommateur à la main sans passer par le script d'exploitation. Je découvre une erreur (NullPointerException). Elle indique que l'exécutable n'a pas trouvé son fichier de configuration. Le lien symbolique vers le répertoire des fichiers spécifiques à l'environnement de production n'existe pas. L'ingénieur système le recrée immédiatement à la main. Il redémarre les consommateurs et une minute plus tard le monitoring repasse au vert. Le service est rouvert et le trafic reprend.
II-B. Une situation client dramatique▲
Où en sommes-nous ? La version cible n'est toujours pas en production. Le pôle exploitation client est passé en incident majeur (plus de deux heures d'interruption de service + retour arrière). Il veut passer en niveau de vigilance maximale sur la prochaine mise en production. C'est-à-dire au minimum avec dix-neuf jours de préavis, avec présentation des changements, solutions de retour-arrière.
De son côté, le pôle marketing-fonctionnel veut publier dans deux semaines une évolution d'une importance inégalée depuis sept ans. Pour assurer cette grosse évolution, il faut effectuer quatre mises en production. En comptant dix-neuf jours de préavis pour chacune, il faudrait trois mois au lieu des deux semaines voulues par le marketing.
II-C. Les « 5 pourquoi »▲
Une fois le service rétabli, je pars mener une enquête minutieuse, dans l'esprit des « 5 pourquoi » du lean (1) pour éviter la réapparition de l'incident.
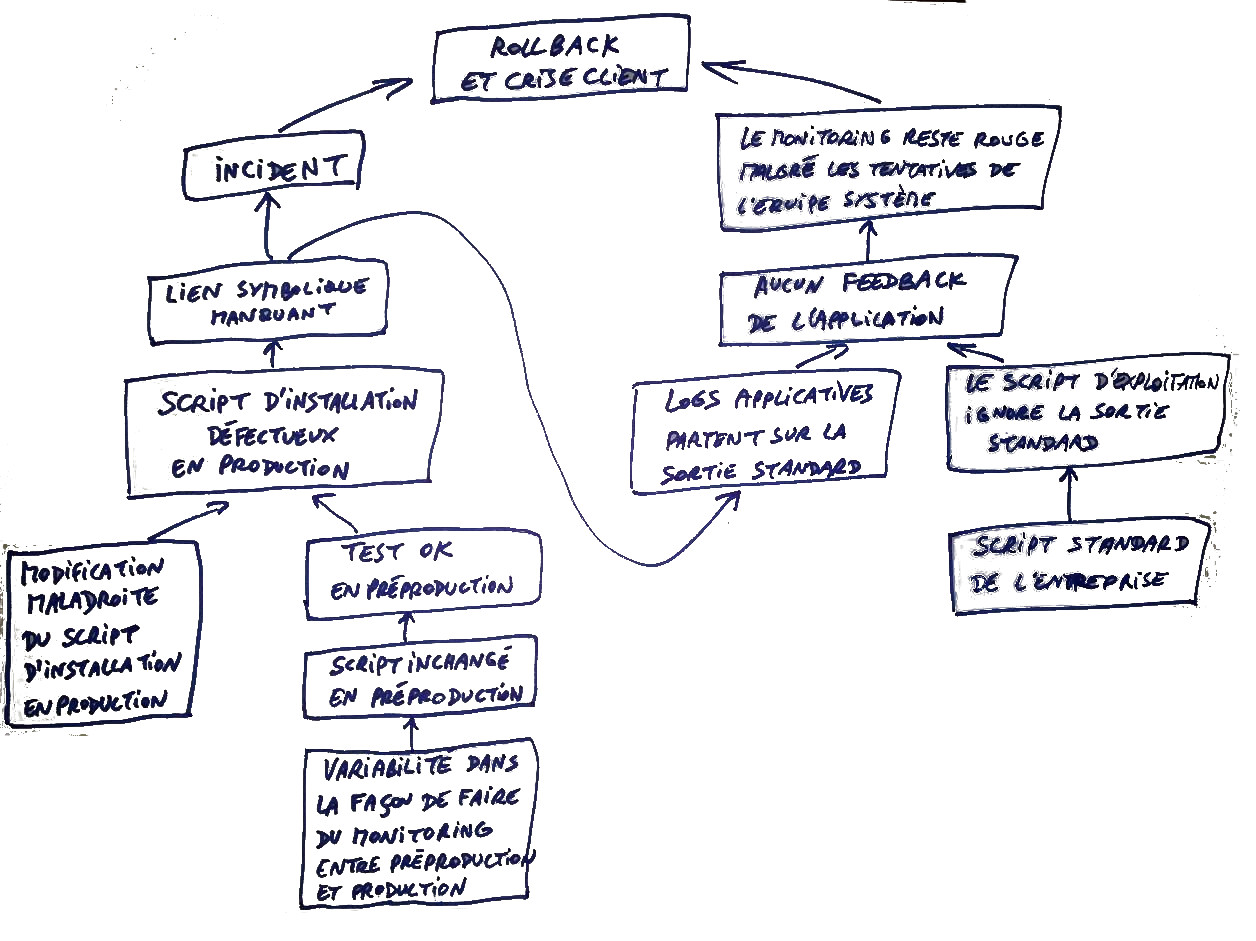
Pourquoi le lien symbolique n'a-t-il pas été créé ? Le script shell d'installation maintenu par l'équipe système n'a pas créé ce lien symbolique.
Pourquoi ? Ce script est composé de deux instructions : une vérification de monitoring et la création du lien symbolique. L'instruction de vérification échoue et interrompt toute l'exécution.
Pourquoi ? Cette instruction se réfère à un chemin inexistant.
Pourquoi ? Ce script a été mal modifié lors d'une mise à jour du système de monitoring.
Une cause profonde (2) a été identifiée : une maladresse lors d'un changement technique.
II-C-1. L'échec des procédures qualité▲
Pourtant, dans mon entreprise, il existe un standard pour se prémunir de ce genre de maladresse, à savoir la répétition systématique en environnement de préproduction.
Pourquoi la répétition en préproduction n'a-t-elle pas révélé ce dysfonctionnement ? Les scripts shell d'installation qui s'y trouvent sont différents de ceux en production : ils n'ont pas été modifiés.
Une autre cause profonde a été identifiée : un écart entre les environnements.
II-C-2. Comment fatiguer son ingénieur système ?▲
Une autre question subsiste : pourquoi un ingénieur système, pourtant talentueux, a-t-il dû attendre l'arrivée d'un développeur pour recréer un lien symbolique ?
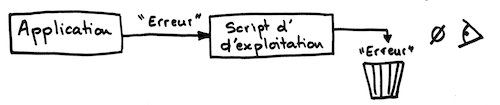
Réponse : lors de l'incident, aucune trace n'apparaissait, ni dans les logs système, ni dans la console.
Pourquoi ? Les logs de l'application partaient vers la sortie standard (à cause du lien symbolique manquant) et le script d'exploitation ignorait la sortie standard.
II-D. Prévenir plutôt que guérir▲
L'arbre de causalité (3) indique trois causes racines, en dehors de notre champ d'action.
Nous modifions notre code pour qu'il adresse à l'ingénieur système un message explicite en cas de dysfonctionnement. En terme lean, nous ajoutons un andon (4).
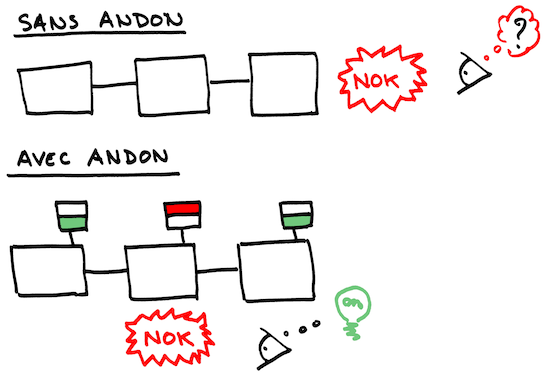
Comme nous avons la main sur le script d'exploitation, nous le modifions pour rediriger la sortie standard, jusque-là ignorée, vers les logs systèmes. Nous ajoutons également la capture de l'exception NullPointerException de manière à informer l'exploitant du problème sur la sortie standard. Pour ne rien laisser au hasard, nous testons ce message auprès de l'ingénieur système pour s'assurer qu'il est compréhensible.
Prochaines investigations à mener :
- comprendre d'où vient la différence entre la préproduction et la production ;
- comprendre pourquoi l'ingénieur système a produit un script défectueux.
Je suis content d'avoir compris ce qui s'était vraiment passé et d'avoir trouvé une contre-mesure peu coûteuse qui empêchera le même désastre de se reproduire.
J'ai la satisfaction d'avoir posé la première pierre du long chemin vers le rétablissement de la confiance avec notre client.
Qu'avons-nous fait ?
- protéger immédiatement le client, avant d'entamer le cycle Plan-Do-Check-Act ;
- trouver les causes racines, avec le « 5 pourquoi » ;
- ajouter un andon dans la chaîne de déploiement applicative pour que l'incident ne se reproduise pas.
Le résultat
Notre application est devenue plus exploitable. Elle met un peu plus notre équipe système en situation de réussir.
Nous avons identifié des sources de variabilité précises, qui vont permettre une investigation plus poussée.
Ce que j'ai appris
Je croyais être impuissant face à un incident qui relevait complètement d'une autre équipe, alors qu'en fait, j'ai pu apporter une contribution qui, à elle seule, évitera de nouveaux incidents.
En tant que développeur, j'ai appris qu'il faut que j'anticipe aussi le cas où le système de log n'arrive pas à s'initialiser.
III. Scène de crime : du rififi dans mes sprints▲
Chaque année, mon équipe agile doit assurer la maintenance d'un site web marchand en plus de son activité de développement. Cette activité ponctuelle perturbe les sprints en cours. (5)
L'équipe met tout d'abord en place un management visuel pour :
- comprendre la situation : les besoins du client et ce à quoi elle doit faire attention lors de la maintenance ;
- voir la nature des dysfonctionnements ;
- être capable de réagir en fonction de la criticité des problèmes.

III-A. Du management visuel au Plan-Do-Check-Act (PDCA)▲
Même si la situation semble s'améliorer, des problèmes déjà corrigés reviennent d'année en année (espace disque insuffisant, fiabilité des statistiques, magasins qui ne présentent pas l'offre…). L'équipe apprend à réagir rapidement aux bons problèmes en protégeant le client par des actions immédiates. Malheureusement, celles-ci ne sont pas pérennes.
Comment s'y prendre pour que la situation s'améliore et que les problèmes identifiés soient corrigés définitivement ?
Je décide de mettre en œuvre la technique du Plan-Do-Check-Act (PDCA).
Sur le management visuel, chaque problème figure sous forme d'un postit.
Un membre de l'équipe est chargé d'analyser le problème en profondeur en utilisant la technique des « 5 pourquoi » (6). Cette technique simple permet de trouver la cause racine du problème.
Ensuite, l'équipier propose une contre-mesure pour supprimer cette cause. Il détermine également un indicateur approprié à la vérification de l'efficacité de la contre-mesure. Suivant le résultat de la vérification, les procédures sont adaptées pour intégrer la nouvelle pratique.
III-B. Le service de prise de commande ne répond pas dans les temps.▲
Le service de prise de commande répond en huit secondes au lieu de deux secondes. Le système de monitoring remonte une alerte sur la console de supervision. Une première investigation identifie la cause principale : un des serveurs dédiés à la prise de commande n'a plus suffisamment d'espace disque.
L'équipe recherche sur le disque la partition incriminée. Elle découvre que le répertoire « /tmp » est plein.
Action immédiate : Un développeur vide le répertoire et tout revient dans l'ordre.
Action définitive : Nous cherchons à résoudre le problème en suivant les étapes du PDCA :
III-B-1. Plan▲
Impact du problème sur le client final :
- le temps de la prise de commande est rallongé de six secondes ;
- il y a un risque que le problème se produise aussi sur les autres machines, empêchant complètement la prise de commande.
L'équipe applique la technique des « 5 pourquoi ».
Le serveur ne répond pas.
- Pourquoi ? le répertoire « /tmp » est plein.
- Pourquoi ? les log binaires prennent toute la place. Ce n'est pas normal que les logs binaires soient présents sur cette machine.
- Pourquoi ? la configuration du serveur n'est pas correcte.
- Pourquoi ? la procédure d'installation ne précise pas qu'il ne faut pas activer les logs binaires sur les serveurs en question.
III-B-2. Do▲
Action 1 : supprimer tous les logs binaires de tous les serveurs dédiés à la prise de commande.
L'analyse de la cause racine a permis d'identifier une seconde action qui devrait permettre d'éviter la réapparition du problème.
Action 2 : désactiver les logs binaires sur tous les serveurs dédiés à la prise de commande.
III-B-3. Check▲
Il n'y a plus de logs binaires dans le répertoire « /tmp » et l'espace disque demeure suffisant pour que l'application fonctionne correctement.
III-B-4. Act / Adjust▲
Après vérification du résultat des actions, la procédure d'installation des serveurs de prise de commande est mise à jour.
III-C. Résultats▲
La pratique du PLAN-DO-CHECK-ACT est appliquée de manière systématique à tous les problèmes rencontrés. Elle a permis d'améliorer les performances d'année en année. Le nombre de réclamations client a diminué de 37 % en deux ans pendant que le trafic augmentait de 40 % et que le nombre de fonctionnalités augmentait d'une dizaine chaque année.
La diminution du nombre de problèmes a permis de limiter l'impact de la maintenance sur la vélocité de l'équipe de développement tout en garantissant la satisfaction de notre client.
Au-delà des bénéfices pour ce projet précis, j'observe que l'enchaînement des cycles Plan-Do-Check-Act fait monter en compétence mon équipe et que les autres projets se passent mieux.
Qu'avons-nous fait ?
- Protéger immédiatement le client, avant d'entamer le cycle Plan-Do-Check-Act.
- Trouver les causes racines, avec le « 5 pourquoi ».
- Effectuer une action corrective à la racine.
- Pérenniser une action d'amélioration en modifiant un standard.
Le résultat
Nous avons diminué significativement le volume d'incidents.
Nous avons un standard corrigé qui nous protège de la récurrence.
Ce que j'ai appris
Mon équipe a acquis des compétences en administration système.
J'ai désormais une expérience personnelle de l'alignement de l'entreprise sur la satisfaction client par le développement des compétences.
IV. Scène de crime : joue-la courte et précise▲
Notre client est mécontent, car l'équipe de développement dont je fais partie met deux fois plus de temps qu'il ne souhaite sur les gros projets.

IV-A. Première hypothèse▲
Pour comprendre où gagner du temps, le Scrum Master propose de visualiser le problème. Il met une feuille au mur, puis chaque développeur qui constate un frein ou un blocage le mentionne sur cet emplacement avec une estimation du temps perdu. Avec beaucoup de discipline, tous les développeurs jouent le jeu.
Au moment où nous compilons les données, nous tombons de haut : nous étions convaincus de trouver un gisement d'améliorations, mais la mesure révèle moins de deux heures perdues par semaine. Ce n'est presque rien comparé aux soixante jours hommes de chaque sprint.
Je réalise que ce n'est pas surprenant. Les gens sont sensibles à ce qui sort de l'ordinaire, mais ne remarquent pas les freins dont ils ont l'habitude.
IV-B. Deuxième hypothèse▲
Mon Scrum Master a une nouvelle intuition : l'équipe passe trop de temps à faire du refactoring. Je trouve pour ma part que l'écriture des tests d'acceptance automatisés est chronophage. Qui a raison ?
Cela mérite une deuxième expérimentation.
Pour éclaircir ce mystère, pendant plusieurs sprints, je note à chaque daily scrum meeting sur quoi nous travaillons :
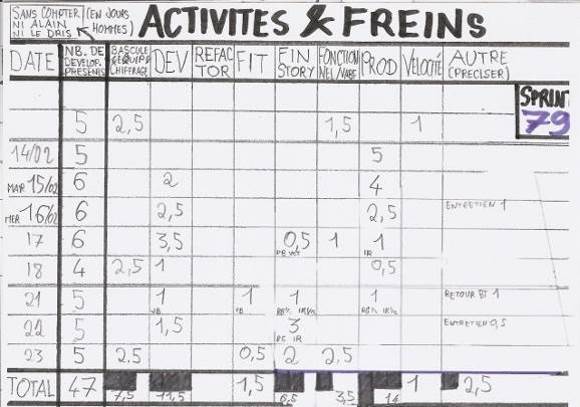
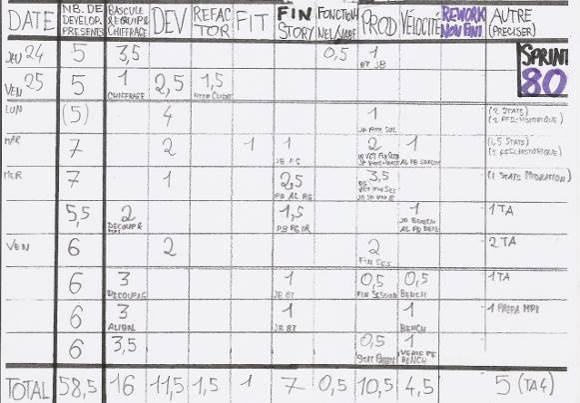
Astuce : préparer un modèle vierge pour assurer une meilleure pertinence des observations récoltées.
Constats : les tests d'acceptance automatisés ne représentent que 5,5 % de notre temps de travail et le refactoring à peine 2 %. L'hypothèse du Scrum Master et la mienne étaient donc toutes les deux fausses.
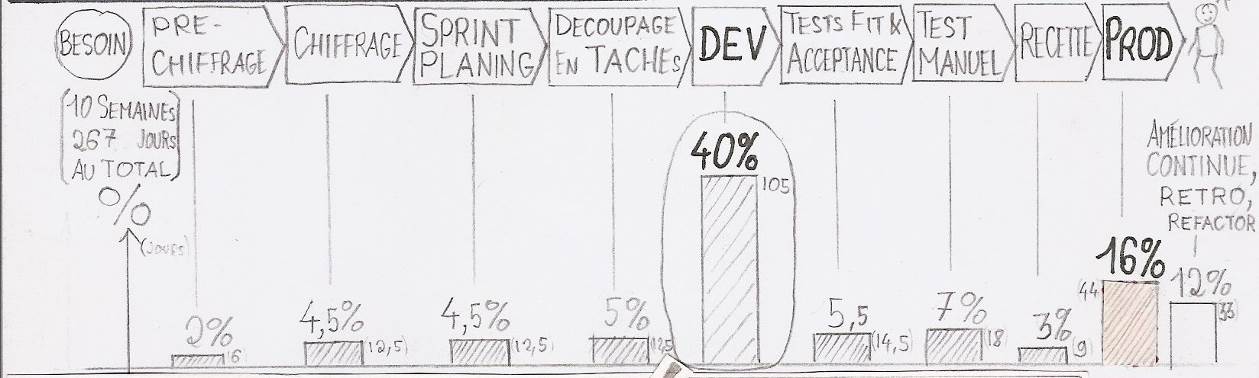
L'élément qui prend le plus de temps est la programmation, avec 40%. Le contraire aurait été étonnant dans une équipe de développement. Mais cela ne fait que déplacer le problème : où passe notre temps quand nous programmons ?
IV-C. Troisième expérimentation▲
Je lance une troisième expérimentation : l'investigation pendant le pair-programming.
Pendant vingt demi-journées, le copilote note le temps passé à la minute près.
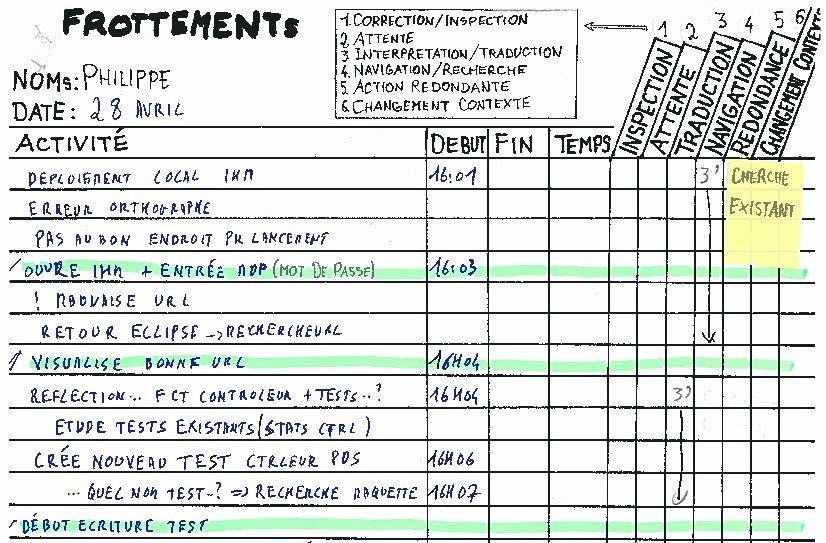
Avant de faire cette expérimentation, nous pensions passer beaucoup de temps dans la rédaction des tests unitaires. D'ailleurs, des confrères agilistes nous disent souvent qu'ils passent entre un tiers et la moitié du temps à écrire des tests. Or, nous constatons que nous y passons moins de 20 % :

Nous imaginions également perdre beaucoup de temps à comprendre et clarifier des spécifications, mais cela ne représente finalement que 4 %.
Champagne ! Nous avons évité de continuer à consacrer des mois et des mois d'amélioration continue à quatre faux problèmes, mais ce n'est pas tout. J'ai vu que notre gaspillage le plus important est de comprendre l'existant. Désormais, quand j'ignore où intervenir pour réaliser ma tâche, je demande systématiquement par quelle classe rentrer dans le code existant et cela me permet d'aller deux fois plus vite.
Qu'avons-nous fait ?
- Convertir une plainte client en un écart quantifié.
- Formuler des hypothèses.
- Préparer des formulaires de collecte de données.
- Tester nos hypothèses avec des mesures.
Le résultat
J'ai obtenu des données factuelles indiquant où passe le temps de l'équipe.
Mon équipe a économisé une énergie colossale en évitant d'investir sur des fausses pistes.
Ce que j'ai appris
J'ai appris un geste qui accélère ma vitesse de développement.
J'ai appris une méthode pour identifier un potentiel d'accélération.
IV-D. Principes lean▲
IV-D-1. Aux origines▲
Le père du lean est convaincu que chacun est rempli d'impressions, de préjugés, d'opinions, qui sont autant d'idées fausses. Ces idées fausses conduisent à des pertes de temps énormes, mais aussi à des conflits puisque chaque problème rencontré est l'occasion de mettre en opposition les préjugés de chacun.
Il utilise une méthode d'apprentissage venue des États-Unis pour éliminer ces idées fausses - une sorte de TDD (Test-Driven Development) pour lutter contre les bugs qui limitent nos raisonnements : le Plan-Do-Check-Act ou PDCA.

Le cycle PDCA
Comme le système mental de chacun est différent, l'apprentissage ne peut être qu'individuel. Un cycle Plan-Do-Check-Act est donc porté par une personne et une seule. Le collectif est quand même présent, mais d'une manière différente de l'agilité : le porteur va voir une par une les personnes impliquées sur leur terrain pour mieux comprendre ce qui se passe. Il présente ses raisonnements pour obtenir des feedbacks. Dans l'exemple « La mise en production qui ne devait pas échouer », c'est un seul développeur qui éclaircit le problème en allant voir les gens. L'exercice est donc individuel, mais pas solitaire.
Plutôt que de s'enliser dans un débat stérile qui naît d'opinions comme « Jean est un très bon ingénieur système, il n'aurait pas modifié ce script sans le tester » ou de généralités comme « le client n'est jamais clair dans sa tête », le praticien du lean est avide de faits : « Combien de fois le client n'a-t-il pas été clair ? Allons voir l'ingénieur système pour savoir ce qui s'est effectivement passé. »
IV-D-2. Qu'est-ce que le Plan-Do-Check-Act apporte à une équipe agile ?▲
Le lean fournit donc une méthode pour affronter des problèmes complexes comme :
- ceux qui reviennent nous hanter et que nous n'arrivons pas vraiment à résoudre définitivement. Dans l'exemple « Du rififi dans mes sprints », les développeurs dépassent la correction rustine et font disparaître toute une classe de problèmes avant même qu'ils ne surviennent ;
- des problèmes qui sortent de la zone de contrôle de l'équipe. Dans l'exemple « La mise en production qui ne devait pas échouer », le développeur trouve la force de traverser les barrières entre production et développement pour creuser jusqu'au cœur de l'incident.
Le problème est présenté au manager d'une manière tellement factuelle qu'aucune trace de rancœur n'y subsiste.
Un développeur peut remettre en cause une pratique de développement contre-productive sans heurter ses coéquipiers.
Toute l'équipe a le cœur net sur ce qui se passe vraiment sur le terrain comme dans « La mise en production qui ne devait pas échouer » où elle se rend compte que les modifications des scripts de monitoring ne sont pas testées.
Enfin, le Plan-Do-Check-Act évite d'investir sur de fausses pistes.
IV-D-3. Comment faire en pratique ?▲
À chaque pas d'un Plan-Do-Check-Act, la méthode préconise que le porteur présente ce qu'il a compris à un expert du sujet et à des acteurs du problème, pour détecter d'éventuelles idées fausses.
IV-D-4. Plan▲
IV-D-4-a. Définir le problème▲
Dans l'exemple « Joue-la courte et précise », le client se plaint d'une dérive des délais. Le membre de l'équipe pense qu'il surestime cette dérive. Le lean transforme cette affirmation en un problème en le visualisant sous la forme d'un écart quantifié entre une attente et un constat. Le porteur se rend compte que les délais sont généralement deux fois plus longs que le client ne le souhaiterait dans le cas des grosses épiques (7) :

IV-D-4-b. Qualifier l'impact▲
Comment juger si le problème mérite l'énergie que le porteur va lui consacrer ? Un bon problème aura un impact significatif pour le client ou l'entreprise (financièrement ou en terme de stratégie).
IV-D-4-c. Comprendre la situation▲
Pour contrer les croyances erronées, le porteur observe, compte, examine des instances du problème. Cette pratique s'appelle le Go&See ou « aller sur le gemba » (8). Elle répond aux questions « À quelle étape, à quel endroit le problème survient-il ? » et « Quel est le potentiel d'amélioration ? »
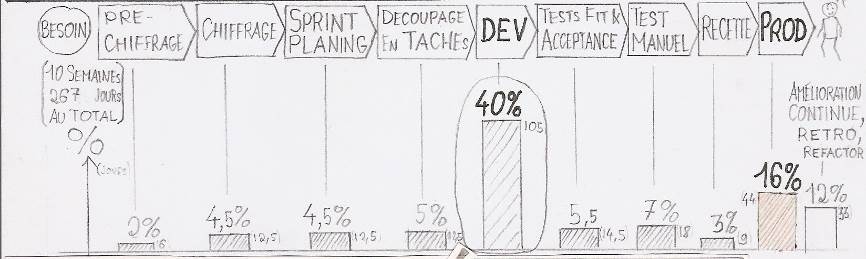
Pour aider à voir le potentiel d'amélioration, le lean met à disposition des outils, qui sont autant de grilles de lecture pour affuter le regard. Le plus connu de ces outils conceptuels est la notion des sept gaspillages (9), c'est-à-dire sept façons différentes de gaspiller le temps précieux d'une personne. Le tableau ci-dessous donne quelques exemples de ces familles dans le contexte du projet de développement agile.
|
Type de gaspillage |
Exemples |
|
Surproduction |
Écrire du code qui n'est jamais utilisé. |
|
Corrections & retouches |
Investigation et correction d'un défaut. |
|
Attente |
Attente de la disponibilité de l'environnement de test. |
|
Stock |
Maintenance d'un backlog de User Stories non développées. |
|
Gestes inutiles |
Navigation dans le code. |
|
Étapes inutiles |
Deux binômes qui réalisent des tâches qui se chevauchent. |
|
Transport |
Reporter des modifications entre différentes branches au sein d'un système de gestion de configuration. |
IV-D-4-d. Trouver les causes racines▲
Le porteur va jusqu'à la cause racine. Dans l'exemple « Du rififi dans mes sprints », poser plusieurs fois la question « pourquoi » amène à découvrir une erreur dans la procédure d'installation de tous les serveurs.
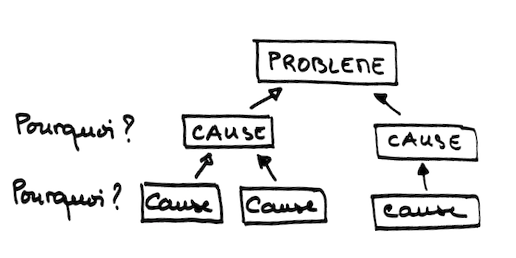
Dans le folklore lean, cette pratique est désignée par le terme « 5 pourquoi ». La consigne littérale est de se poser cinq fois d'affilée la question « pourquoi ? ». Cependant, le chiffre 5 est une invitation à creuser plus que d'habitude, et non pas une règle. Il faut aussi se méfier de réponses qui s'écarteraient des faits pour tendre vers des accusations.
Les enchaînements cause-conséquence peuvent être représentés sous forme d'arbre.
Des hypothèses sont ainsi formulées et testées. Dans l'exemple « Joue-la courte et précise », la croyance « une équipe extreme programming passe la moitié de son temps à écrire des tests » est invalidée.
IV-D-4-e. Formuler puis choisir des contre-mesures▲
Une fois les causes bien comprises, le porteur fait un exercice de pensée divergente : il imagine un maximum de contre-mesures pour adresser les différentes causes. Le lean privilégie les contre-mesures ingénieuses, économes et dont l'effet peut être vérifié rapidement.
L'exemple « La mise en production qui ne devait pas échouer » illustre cet état d'esprit de l'amélioration continue. Le développeur aurait pu dire « c'est inadmissible ce que fait l'équipe système, à eux de s'améliorer en réalignant préproduction et production, en testant les scripts d'installation ». Pourtant, il choisit coûte que coûte d'apporter une petite contribution. Il réussit ainsi sa journée à double titre : en rétablissant le système le matin et en améliorant le feedback de l'application le soir.
IV-D-4-f. Formuler la méthode de Check▲
Le porteur explique comment il va vérifier factuellement si sa contre-mesure fonctionne.
IV-D-4-g. Do▲
La phase Do correspond à la mise en œuvre de la contre-mesure choisie.
IV-D-4-h. Check▲
Le Check est la vérification factuelle de l'impact de la contre-mesure, comme prévu durant le Plan. Un Check peut être soit OK, si les objectifs visés sont atteints. Sinon il est NOK.
Dans l'exemple « Du rififi dans mes sprints », l'équipe mesure une diminution de 37 % des incidents. Son Check est OK.
IV-D-4-i. Act▲
Durant la phase Act, le porteur pérennise les enseignements qu'il tire de ses expérimentations. Dans l'exemple précédent, l'équipe corrige la procédure d'installation de ses serveurs.
Que le Check soit OK ou NOK, il y a toujours quelque chose à apprendre d'une expérimentation bien menée. Le plus beau succès est de pouvoir se dire « J'étais persuadé de X, en fait, j'avais tort ! ».
V. Premiers pas▲
La résolution de problème est une technique puissante, mais à manier avec précaution. C'est pourquoi nous vous invitons à suivre scrupuleusement les sept étapes qui suivent.
V-A. Choisir un sujet▲
Choisissez un sujet qui est important pour vous. Posez-vous la question de la dernière difficulté majeure que vous avez rencontrée ou du problème qui revient le plus souvent.
V-B. Formuler le problème▲
Formulez-le sous forme d'écart entre :
- ce que vous constatez ;
- ce que vous voudriez à la place.
V-C. Identifier l'impact▲
Répondez à la question : pourquoi est-ce important ?
Vérifiez qu'il y a un impact significatif pour le client ou pour l'entreprise. (cf. chapitre « De Satisfaire le client à Comprendre le client »).
V-D. Définir l'écart au standard▲
Quand ce problème se manifeste, qu'observez-vous ?
V-E. Chercher les causes racines▲
Qu'est-ce qui provoque ce problème ? Énumérez toutes les hypothèses qui vous semblent plausibles.
L'important est de trouver des hypothèses testables.
V-F. Vérifier les hypothèses▲
Trouvez le moyen le plus simple et rapide de confirmer vos hypothèses.
V-G. Définir le résultat attendu▲
Avant d'entreprendre les actions correctives, définissez où, quand et comment vous pourrez vérifier qu'elles auront porté leurs fruits.
VI. Aller plus loin▲
- Toyota Kata de Mike Rother - Edition McGraw-Hill
- Managing to learn de John Shook - Edition Lean Enterprise Institute, Inc.
- Understanding A3 thinking de Durward K. Sobek II. et Art Smalley - Edition Productivity Press
Vous pouvez réagir par rapport à ce guide sur le forum : 3 commentaires ![]()
